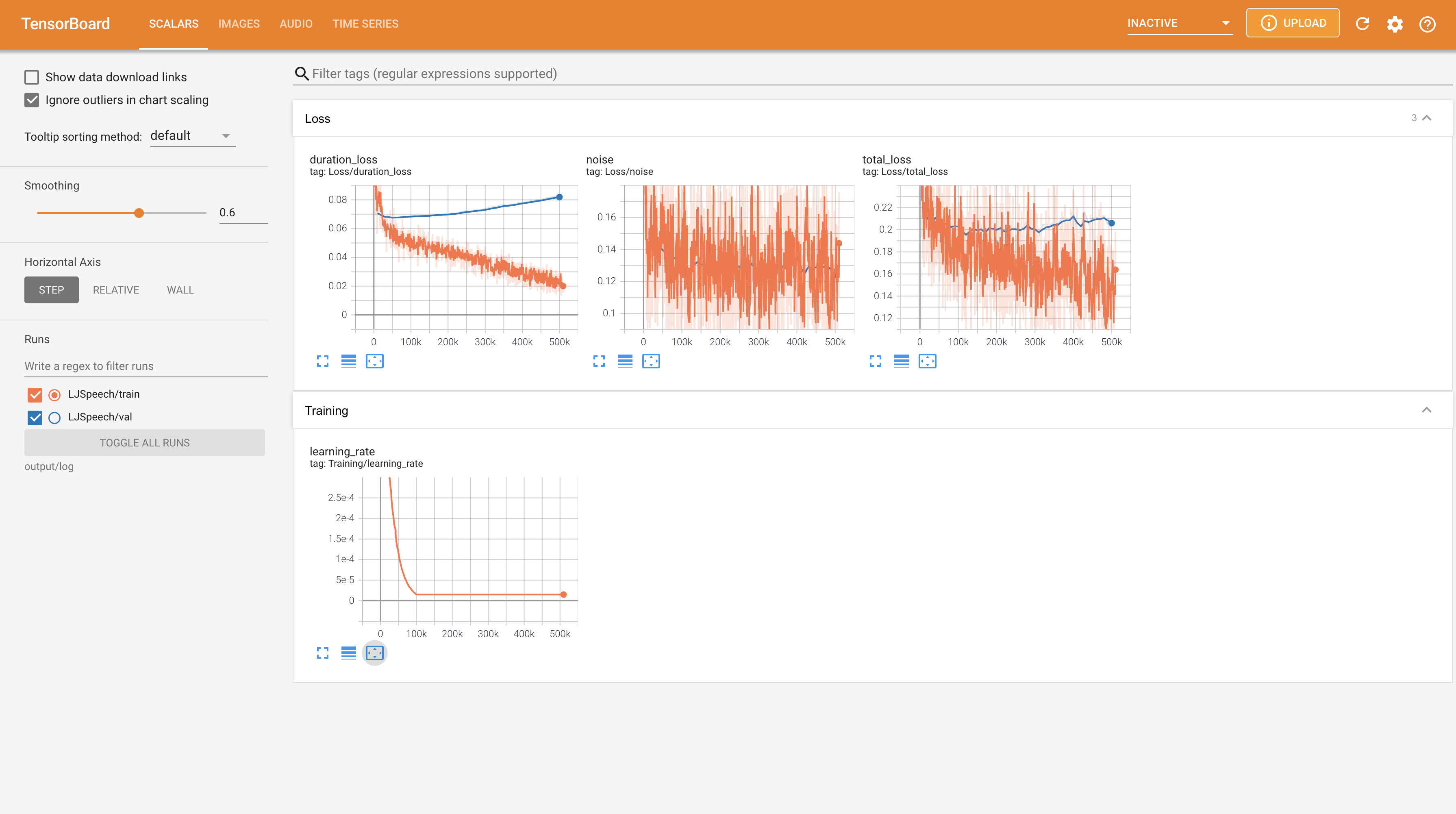
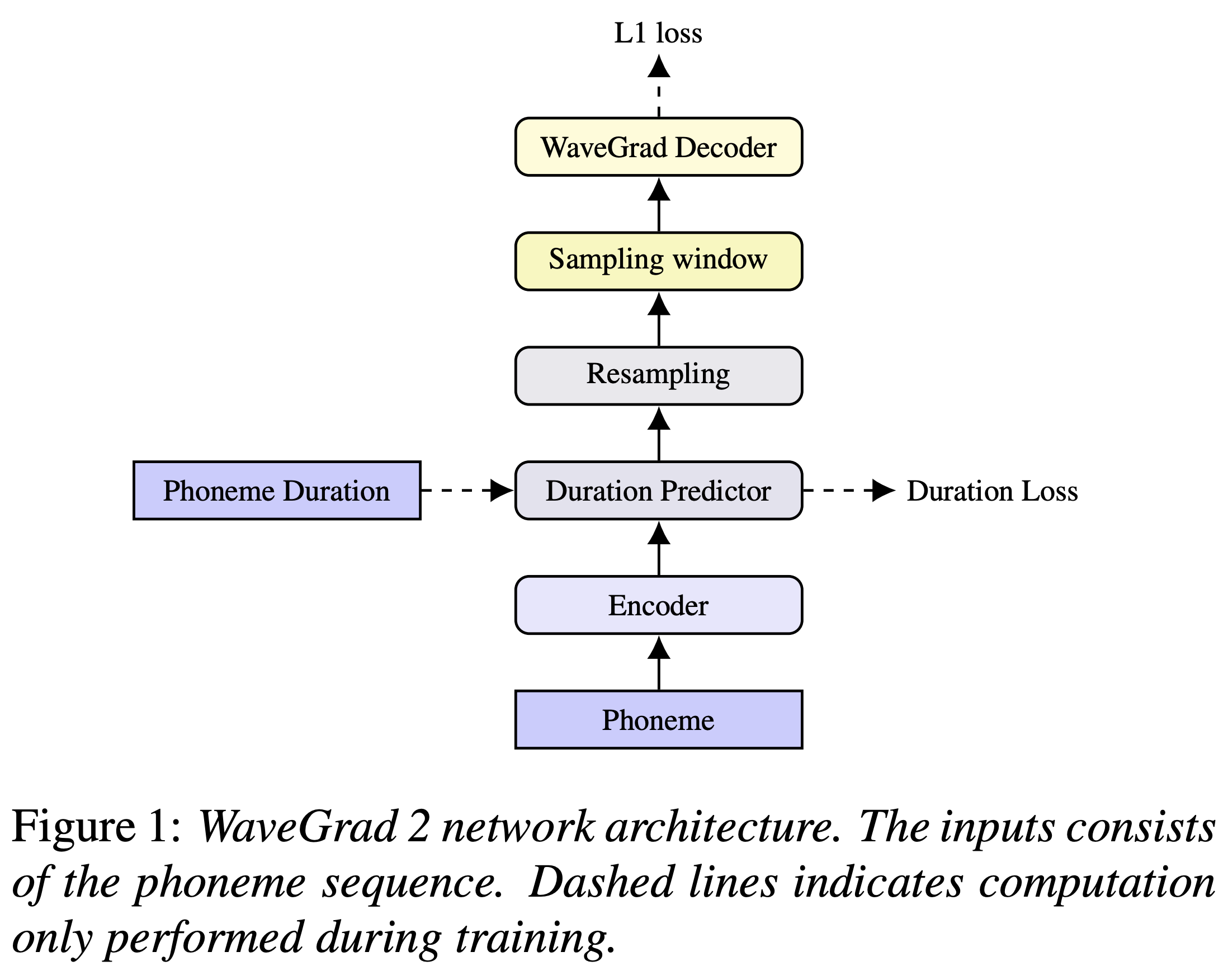
WaveGrad2 is a non-autoregressive generative model designed for high-fidelity TTS. Unlike traditional models that rely on mel-spectrograms, WaveGrad2 directly generates audio waveforms from phoneme sequences through a score-matching approach. It employs an iterative refinement process, starting from Gaussian noise and progressively denoising over multiple steps to reconstruct the audio signal. This method offers a natural trade-off between inference speed and sample quality by adjusting the number of refinement steps. WaveGrad2 achieves performance comparable to state-of-the-art neural TTS systems while maintaining flexibility in generation speed and quality .
Key Features
Direct Waveform Generation: Generates audio waveforms directly from phoneme sequences without the need for mel-spectrograms.
Iterative Refinement: Utilizes a multi-step denoising process to progressively refine the audio signal.
Flexible Inference: Allows adjustment of refinement steps to balance between generation speed and audio quality.
High-Fidelity Output: Produces high-quality audio comparable to state-of-the-art TTS systems.
PyTorch Implementation: Provides a PyTorch-based implementation for ease of use and integration.
Pretrained Models: Includes pretrained models for quick deployment and experimentation.
Comprehensive Documentation: Offers detailed instructions and examples for setup and usage.
.png)

.png)

.png)
.png)
.png)