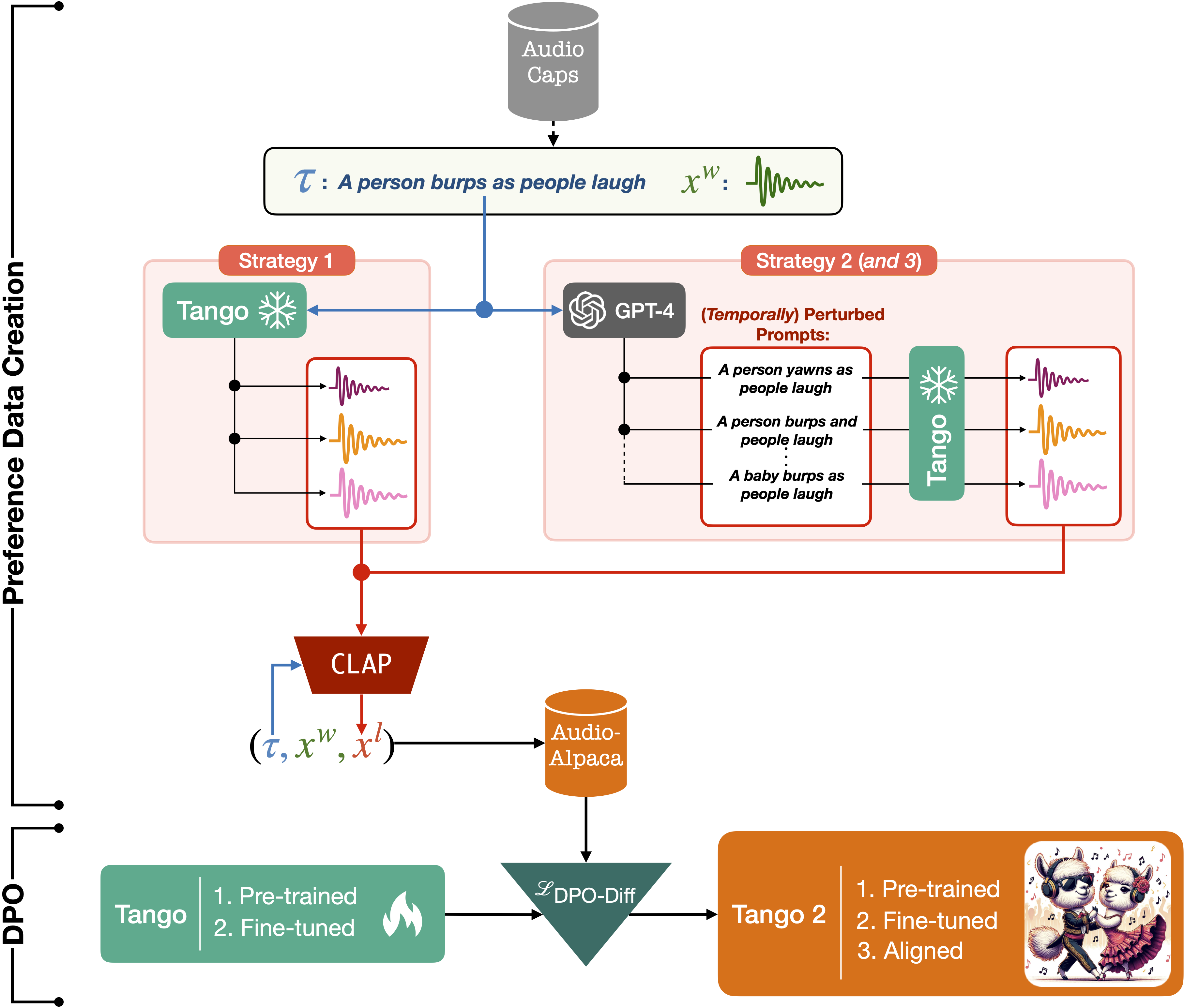
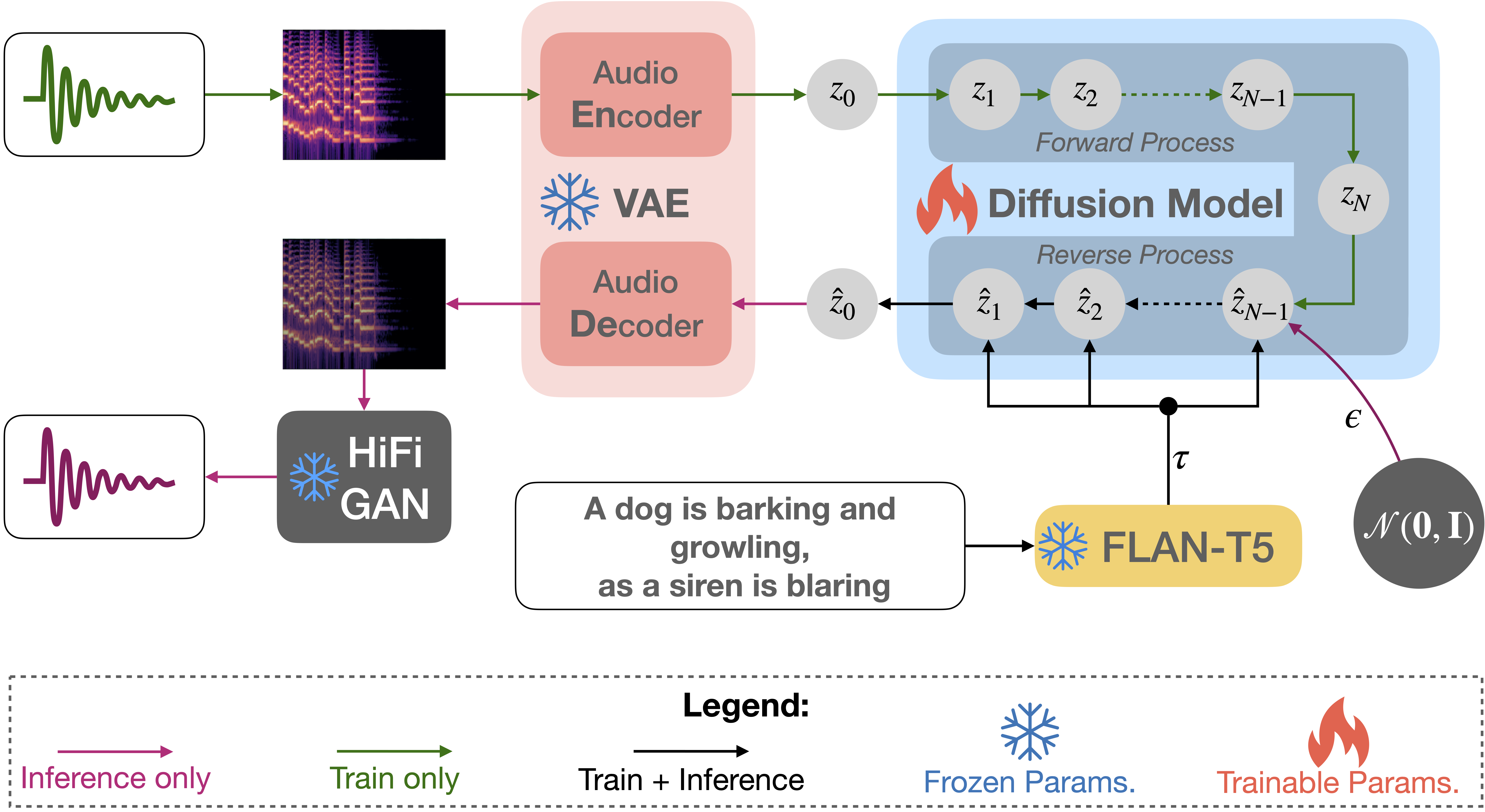
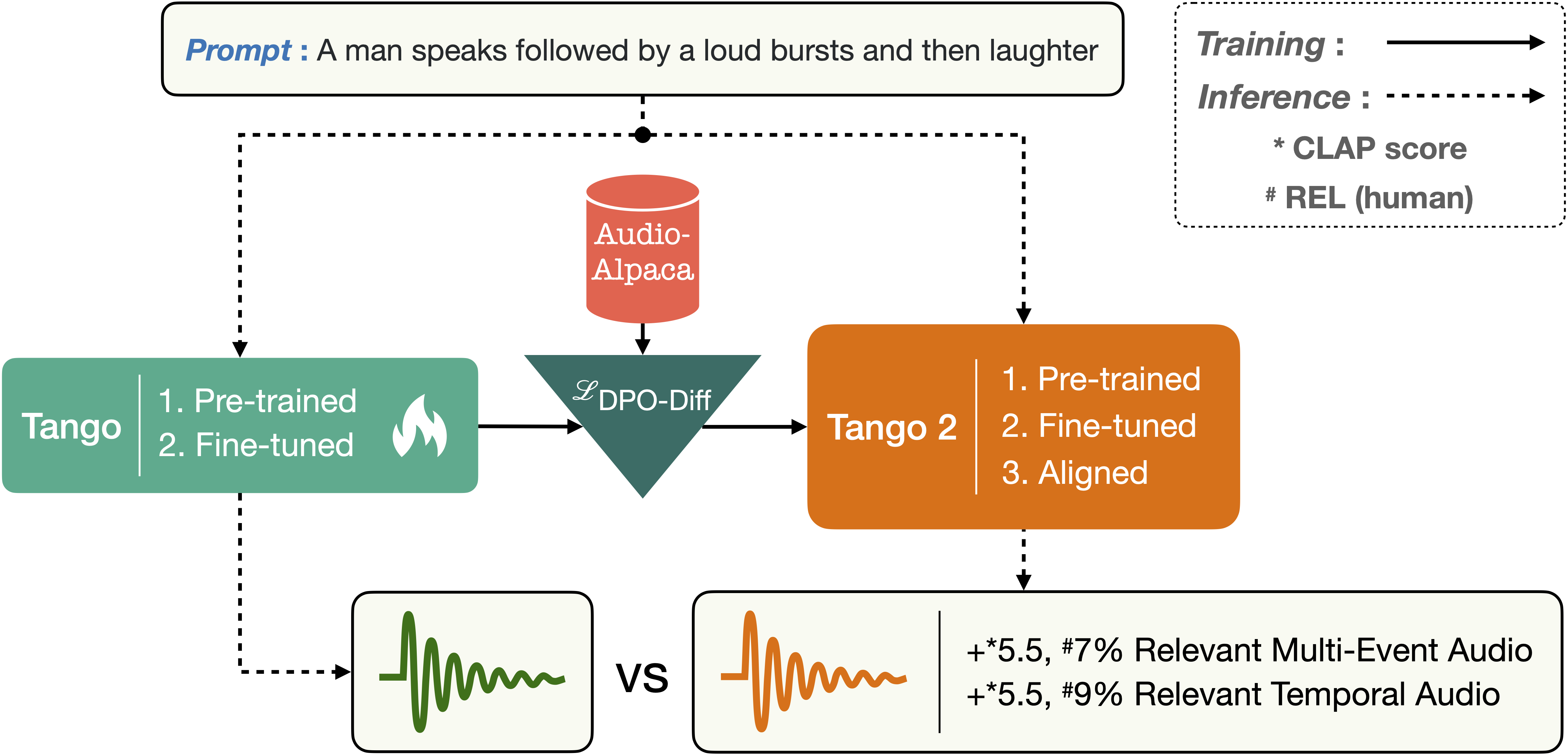
Tango is a family of latent diffusion models for generating high-quality audio conditioned on text prompts. It employs an instruction‑tuned LLM (Flan‑T5) as a prompt encoder and a UNet‑based latent diffusion model. Despite using a dataset ~63x smaller than many prior works, Tango matches or surpasses state‑of‑the‑art performance on benchmarks like AudioCaps. Tango 2 further enhances results by aligning generations via direct preference optimization (DPO) using the Audio‑Alpaca dataset
Key Features
Text-to-audio generation supporting speech, sound effects, and music
Instruction-tuned Flan-T5 prompt encoder (frozen during training)
Latent diffusion model with audio VAE and vocoder architecture
Competitive performance with much less training data
Tango 2 includes alignment via Direct Preference Optimization (DPO)



.png)
.png)
.png)
.png)