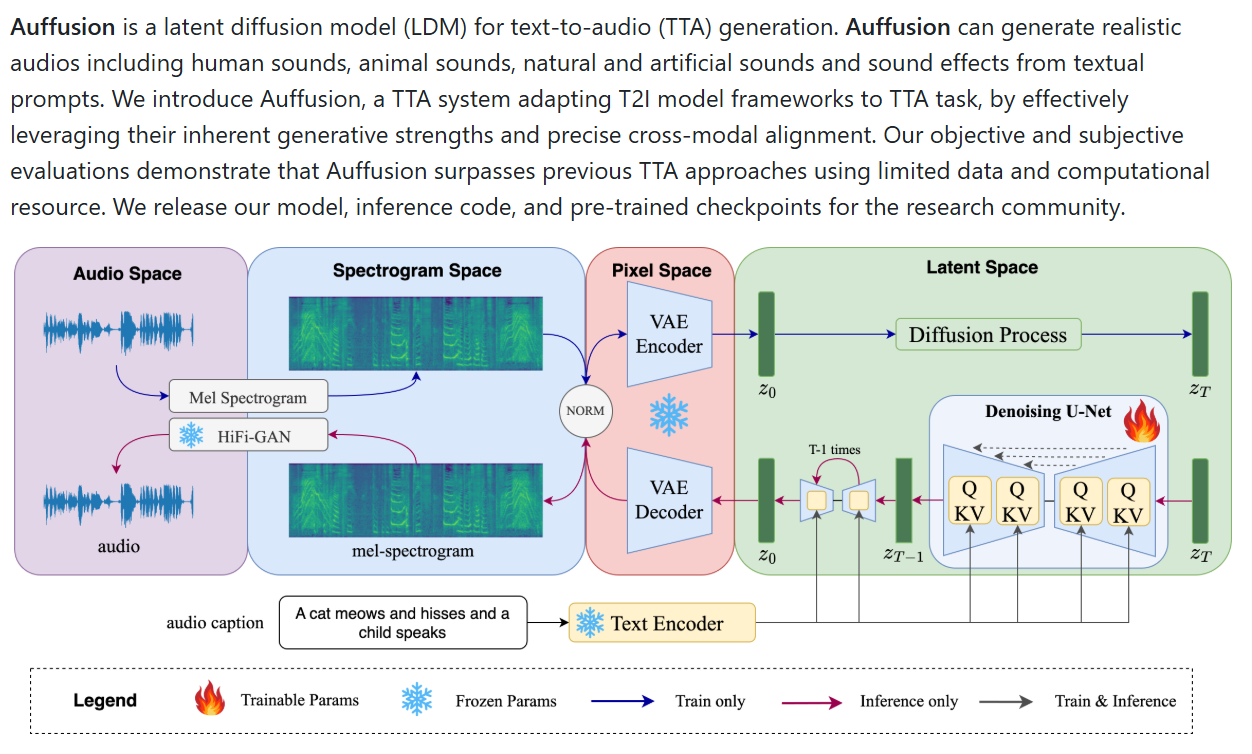
Auffusion is a latent diffusion model (LDM) tailored for generating realistic audio from textual prompts. It effectively adapts state-of-the-art text-to-image (T2I) frameworks to the text-to-audio (TTA) domain, enabling the synthesis of human speech, animal sounds, environmental noises, and sound effects with high fidelity and precise cross-modal alignment.
Key Features
Latent Diffusion Architecture: Utilizes a latent diffusion model to generate audio in the latent space, enhancing efficiency and quality.
Cross-Modal Alignment: Incorporates large language models to ensure accurate alignment between text inputs and audio outputs.
Versatile Audio Generation: Capable of producing a wide range of audio types, including speech, animal sounds, and environmental noises.
Advanced Manipulation Capabilities: Supports tasks such as audio style transfer, inpainting, and prompt-guided audio editing.
Pretrained Models and Inference Tools: Provides pretrained models and inference scripts to facilitate easy deployment and experimentation.
Comprehensive Documentation: Includes detailed notebooks and examples to guide users through setup and usage.
.png)
.png)
.png)
.png)
.png)
.png)
.png)