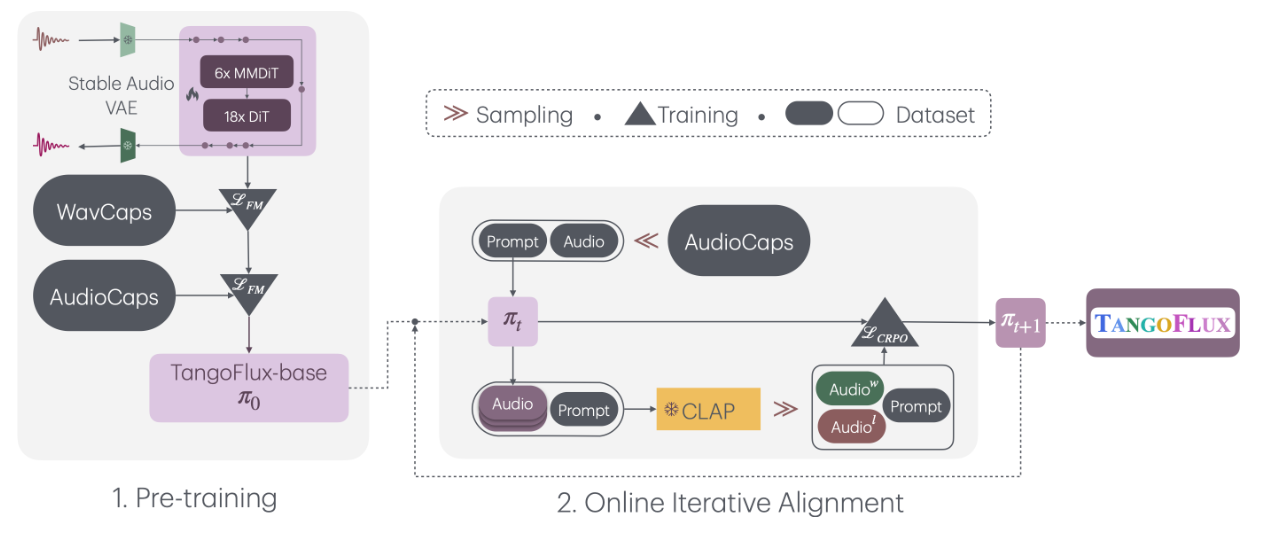
TangoFlux is a next-generation audio generation model that uses flow-matching with diffusion transformers conditioned on text and duration embeddings. It produces high-fidelity, 44.1 kHz stereo audio up to 30 seconds long in just a few seconds per sample. Its three-stage pipeline—pretraining, fine-tuning, and preference alignment using CRPO—ensures both speed and quality.
Key Features
Uses FluxTransformer architecture with advanced transformer blocks for latent audio generation
Duration-conditioned flow-matching allows generation of variable-length audio up to 30 seconds
Fast inference speed, generating 30-second audio in just a few seconds
Three-stage training pipeline: pretraining, fine-tuning, and preference optimization
Comes with pretrained models, a Python API, command-line tools, and a web interface for easy use
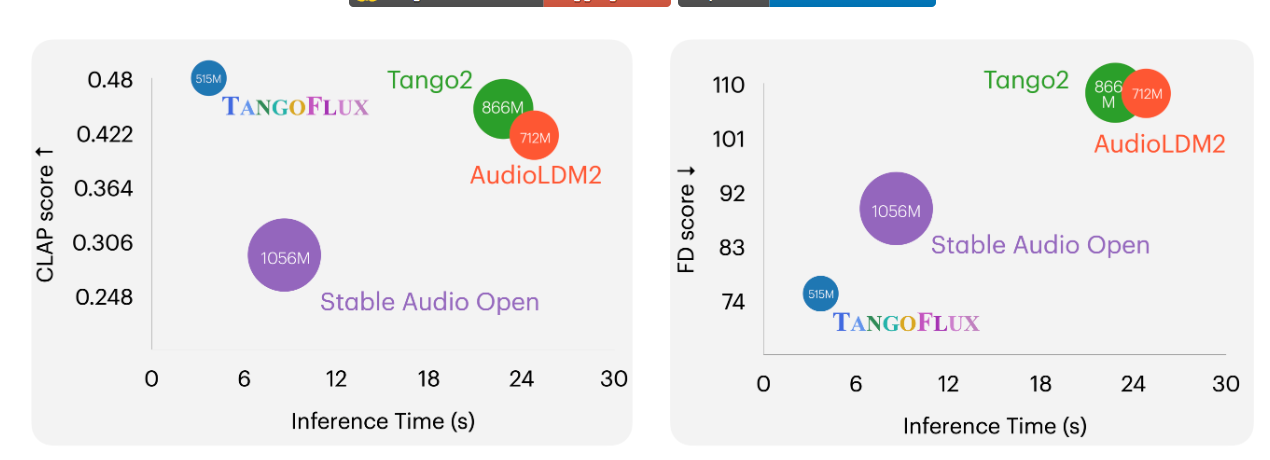
Demonstrated improved audio quality metrics with fewer parameters and lower latency compared to previous models
.png)


.png)
.png)

.png)