StreamSpeech is a unified audio model that performs offline and real-time speech tasks in a single framework. It seamlessly handles speech recognition (ASR), speech-to-text translation (S2TT), speech-to-speech translation (S2ST), and text-to-speech synthesis (TTS) under various latency conditions. Designed for simultaneous streaming applications, it outputs transcription, translation, and synthesized speech incrementally as audio is received.
Key Features
Eight integrated tasks: offline ASR, S2TT, S2ST, TTS, and their streaming (simultaneous) equivalents
Streaming policy control: intelligently decides when to start translating and speaking based on CTC alignment
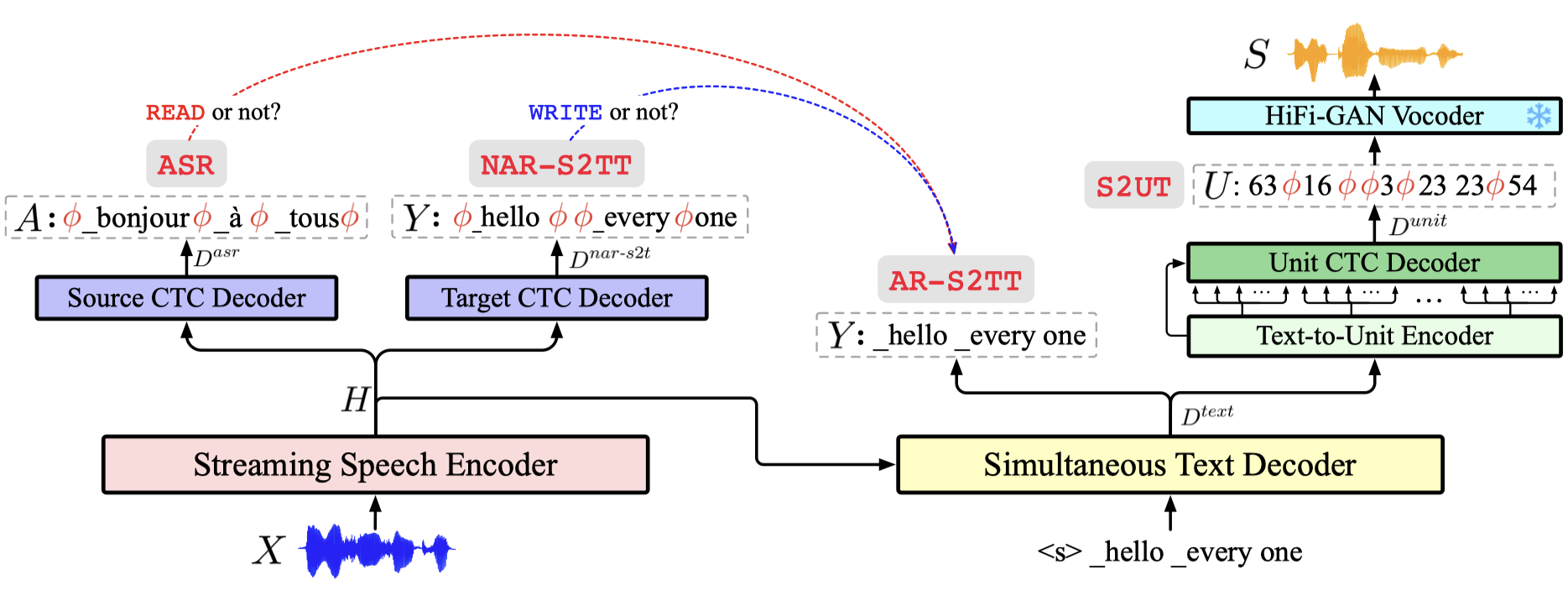
Two-pass architecture: streaming speech encoder → text decoder → text-to-unit module → vocoder for speech generation
Chunk-based Conformer encoder: supports both local context and continuous encoding without bi-directional latency overhead
Multi-task training: jointly optimizes ASR, NAR-S2TT, AR-S2TT, and speech-to-unit conversion
Dynamic latency control: uses variable chunk sizes during training to adapt seamlessly to different latency requirements
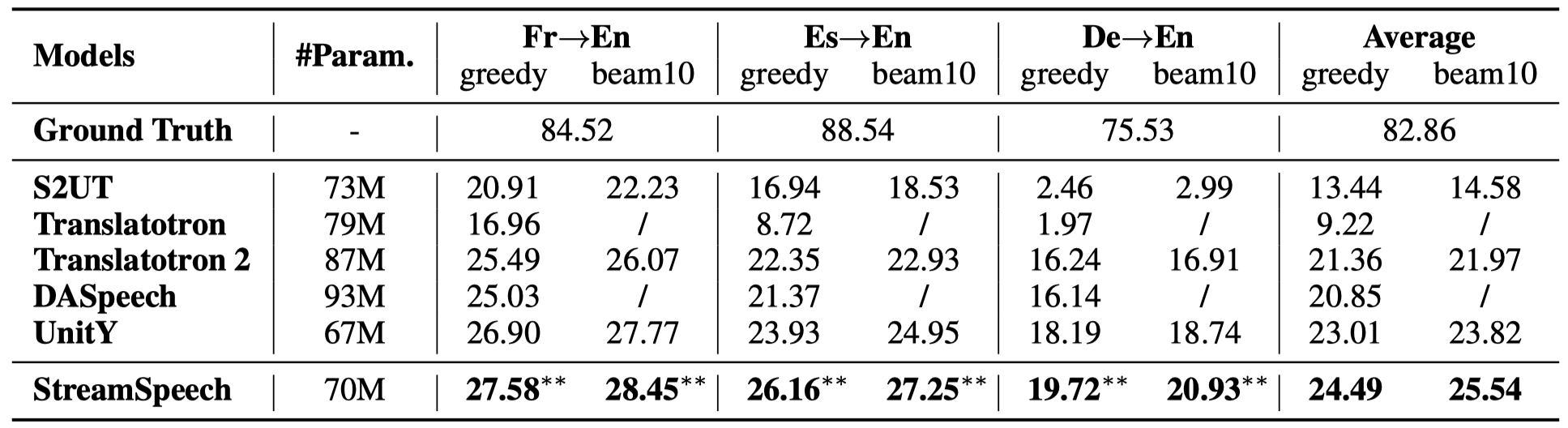
Pretrained multilingual models: supports French→English, Spanish→English, and German→English for both offline and streaming paths
.png)
.png)
.png)
.png)

.png)
.png)