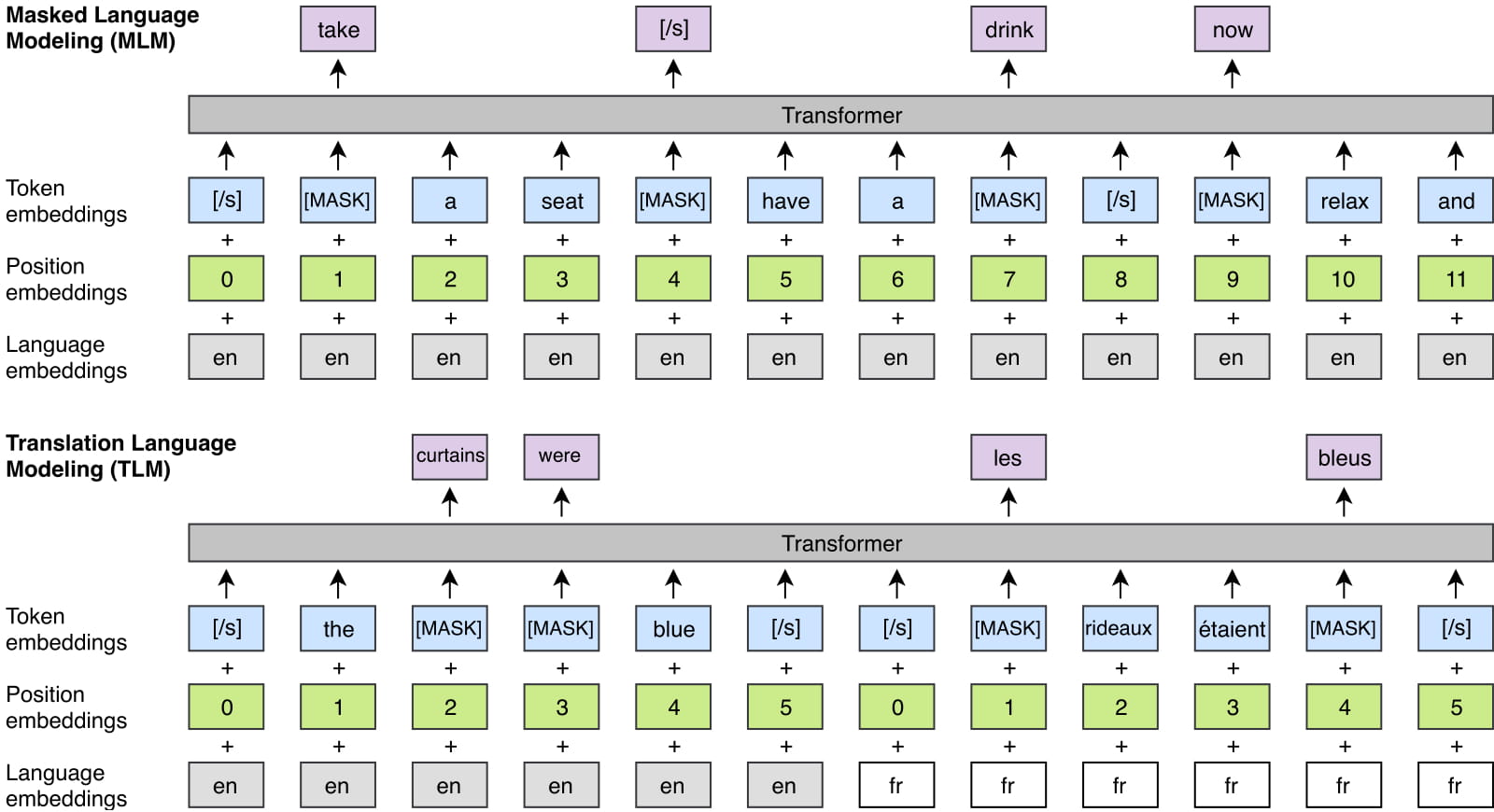
XLM is a PyTorch-based implementation designed for cross-lingual language model pretraining. It supports both monolingual and cross-lingual training objectives, enabling applications such as machine translation, cross-lingual classification, and multilingual understanding. The model introduces techniques like Translation Language Modeling (TLM) to enhance performance across multiple languages. XLM has demonstrated state-of-the-art results on various benchmarks, including XNLI and GLUE.
Key Features
Monolingual and Cross-lingual Pretraining: Supports Causal Language Modeling (CLM), Masked Language Modeling (MLM), and Translation Language Modeling (TLM) objectives.
Multilingual Support: Trained on data from multiple languages, facilitating cross-lingual tasks.
Applications: Suitable for supervised and unsupervised machine translation (NMT/UNMT) and cross-lingual text classification tasks.
Scalability: Supports multi-GPU and multi-node training setups.
Integration: Includes scripts and tools for data preprocessing, model training, and evaluation on standard benchmarks.
.png)
.png)
.png)

.png)