ELECTRA is a transformer-based language model that introduces a more sample-efficient pretraining method by replacing masked language modeling with a discriminative task. Instead of predicting masked tokens, ELECTRA trains a model to distinguish between real and fake tokens generated by a small generator model. This results in faster training and improved downstream performance compared to traditional methods like BERT.
Key Features
Uses a generator-discriminator setup for efficient pretraining
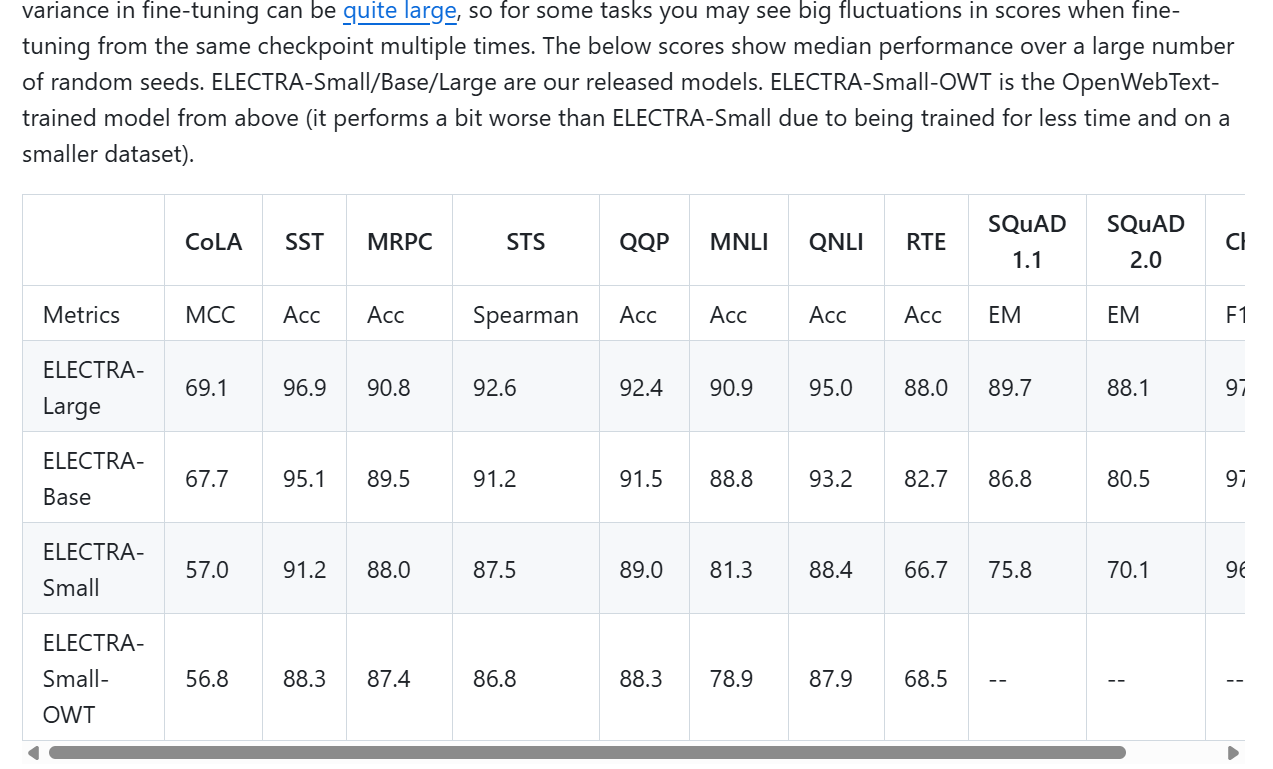
Achieves better performance with significantly fewer training steps
Outperforms BERT on several NLP benchmarks with less compute
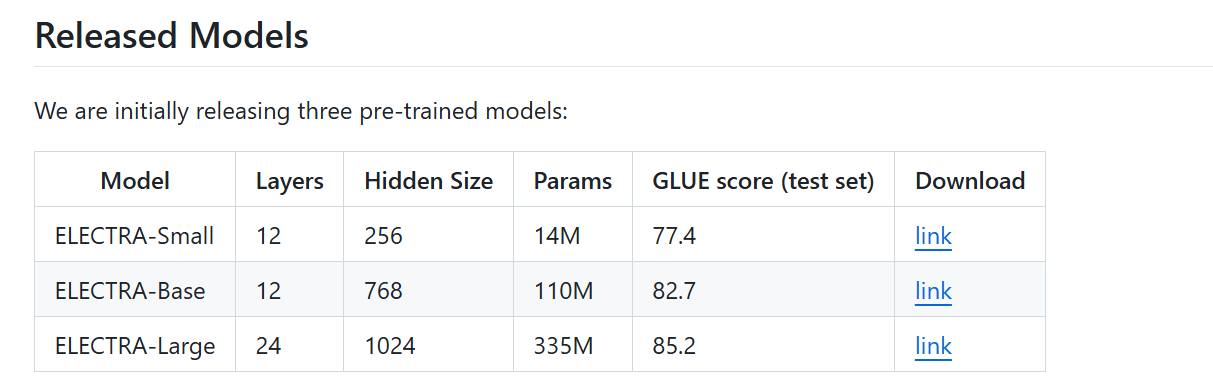
Provides pretrained models and training scripts in TensorFlow
Suitable for a wide range of tasks including classification and QA
.png)
.png)

.png)
.png)