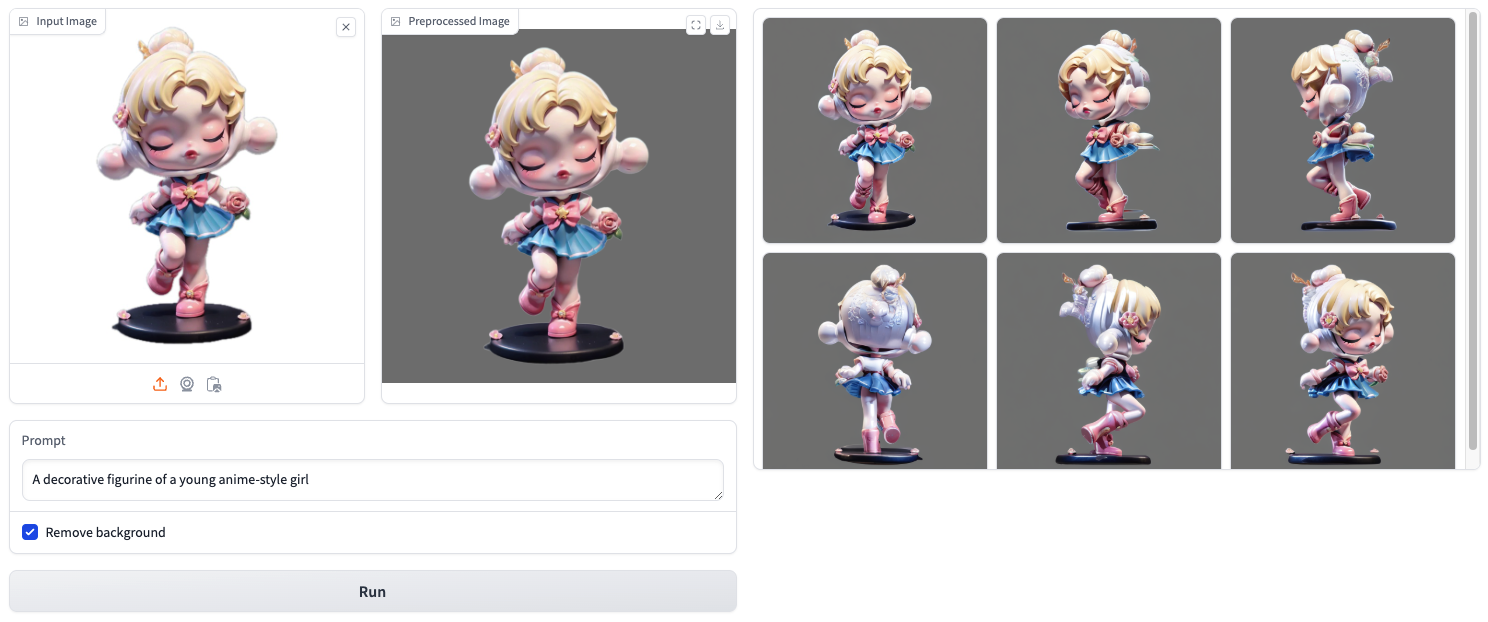
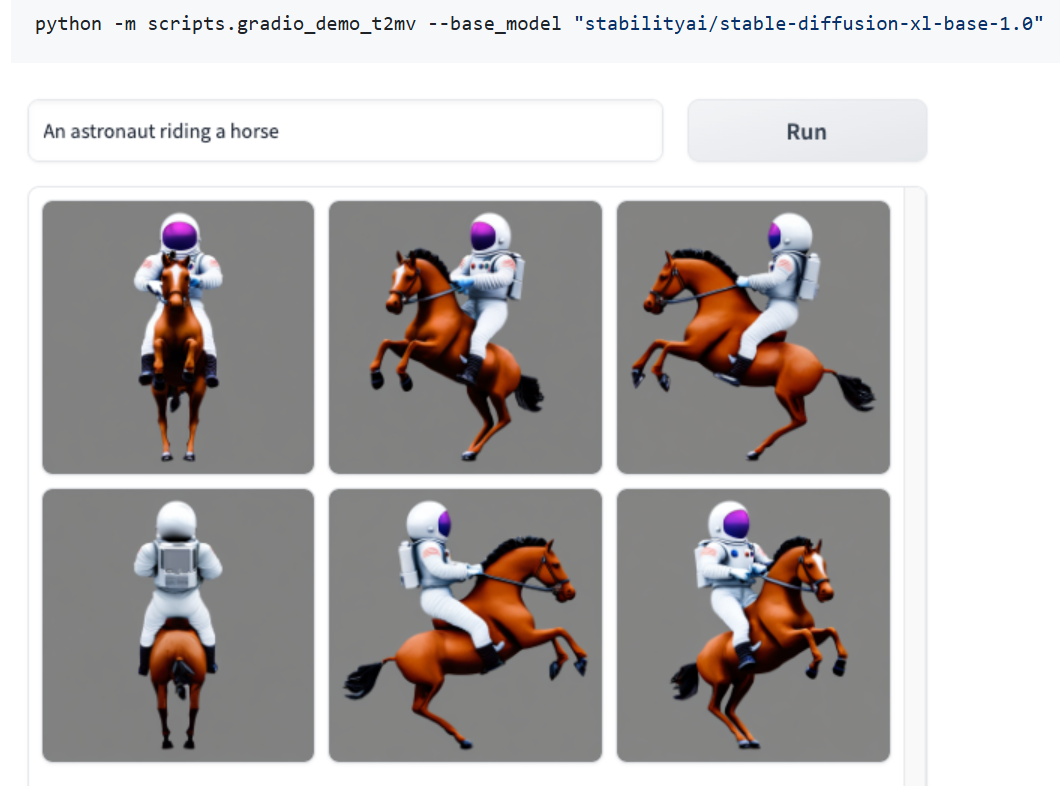
MV-Adapter is a plug-and-play adapter designed to extend pre-trained text-to-image diffusion models, such as Stable Diffusion XL (SDXL), enabling them to generate multi-view consistent images. By integrating geometric priors and camera conditions, MV-Adapter facilitates applications like 3D reconstruction, texture synthesis, and multi-view rendering without the need for extensive retraining or architectural modifications.
Key Features
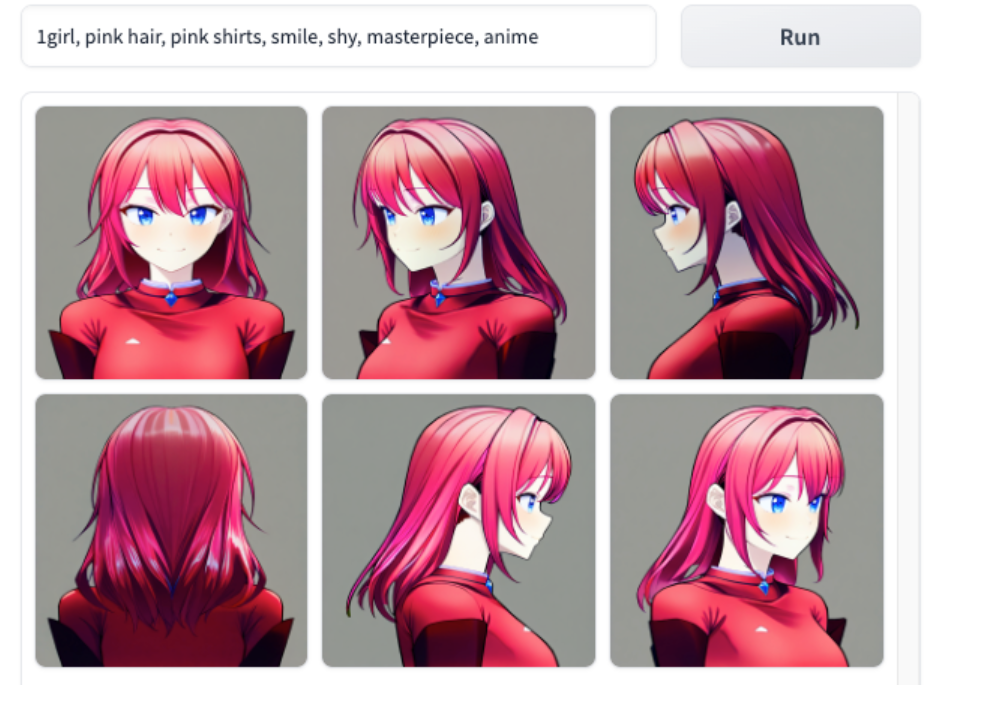
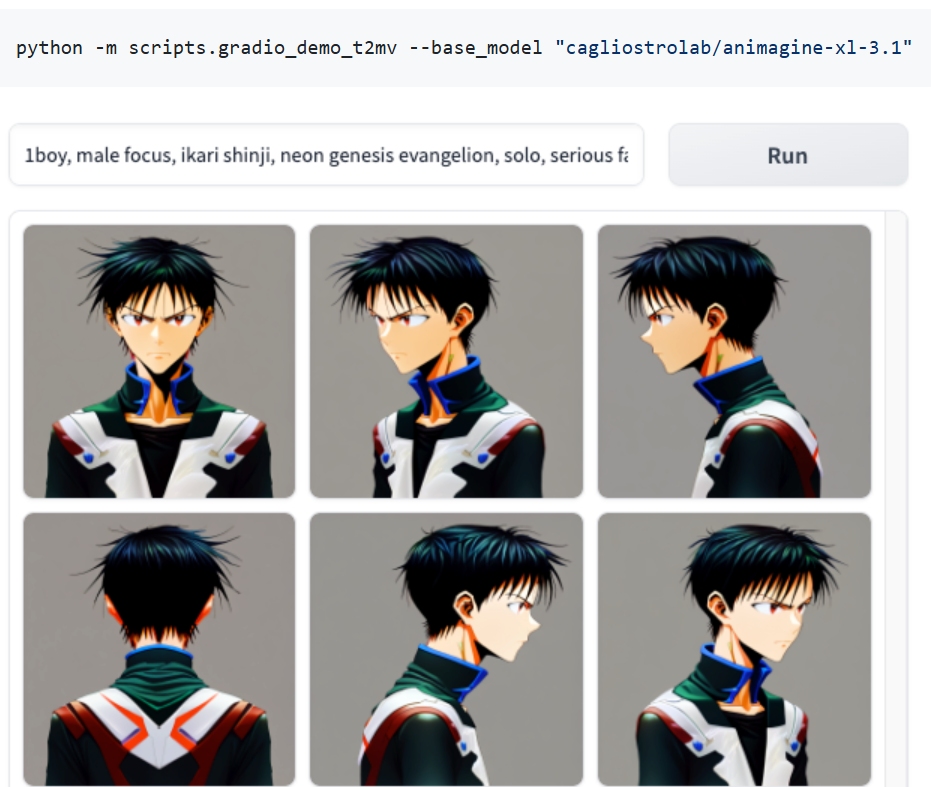
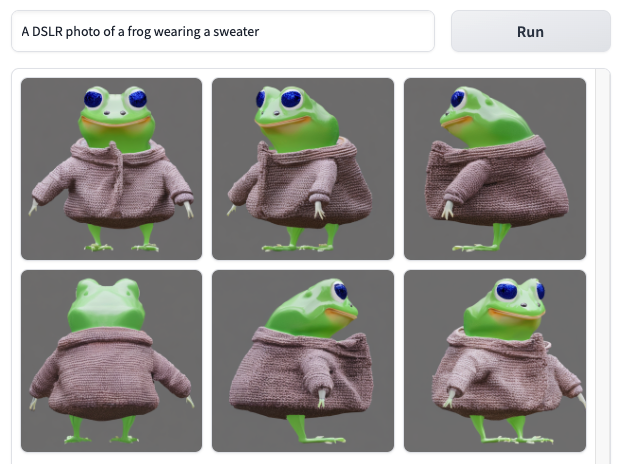
Multi-View Image Generation: Produces consistent images from various viewpoints (e.g., front, back, side) using text or image prompts.
High-Resolution Output: Supports image generation at resolutions up to 768×768 pixels.
Compatibility: Works seamlessly with personalized models (e.g., DreamShaper), distilled models (e.g., LCM), and extensions like ControlNet.
Geometry-Guided Generation: Utilizes camera parameters and geometric information to guide the generation process.
Efficient Training: Employs decoupled attention layers and a unified condition encoder, reducing computational overhead while preserving model performance.
Integration with ComfyUI: Provides custom nodes for easy integration into the ComfyUI interface, enhancing user experience
.jpg)

.jpg)
.png)
.png)
.png)

.png)