This repository contains the code for a master's thesis project focused on VideoBERT, a model designed to learn joint representations of video and text. The project involves several steps, including data collection from the HowTo100M dataset, feature extraction using the I3D model, clustering of features, and training a VideoBERT model for tasks such as video captioning and masked language modeling. The implementation is based on Hugging Face's Transformers library
Key Features
Data Collection: Gathering videos and text annotations from the HowTo100M dataset.
Data Transformation: Adjusting frame rates and adding punctuation to text annotations.
Feature Extraction: Using the I3D model to extract features from videos.
Clustering: Applying hierarchical k-means clustering to group video features.
Model Training: Training a VideoBERT model using the processed data.
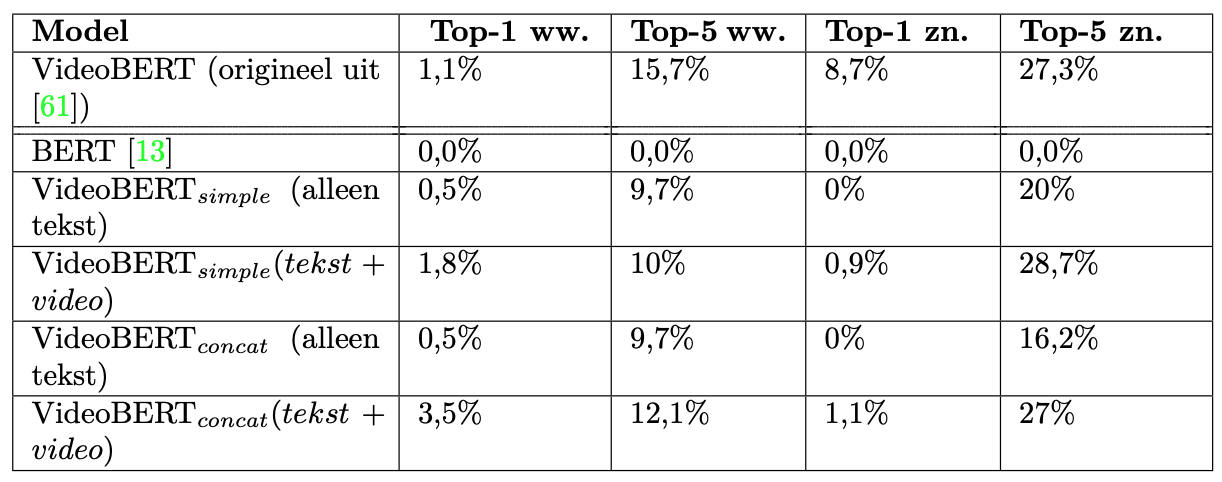
Evaluation: Assessing the model's performance on the YouCookII validation dataset.
.png)



.png)
.png)

.png)