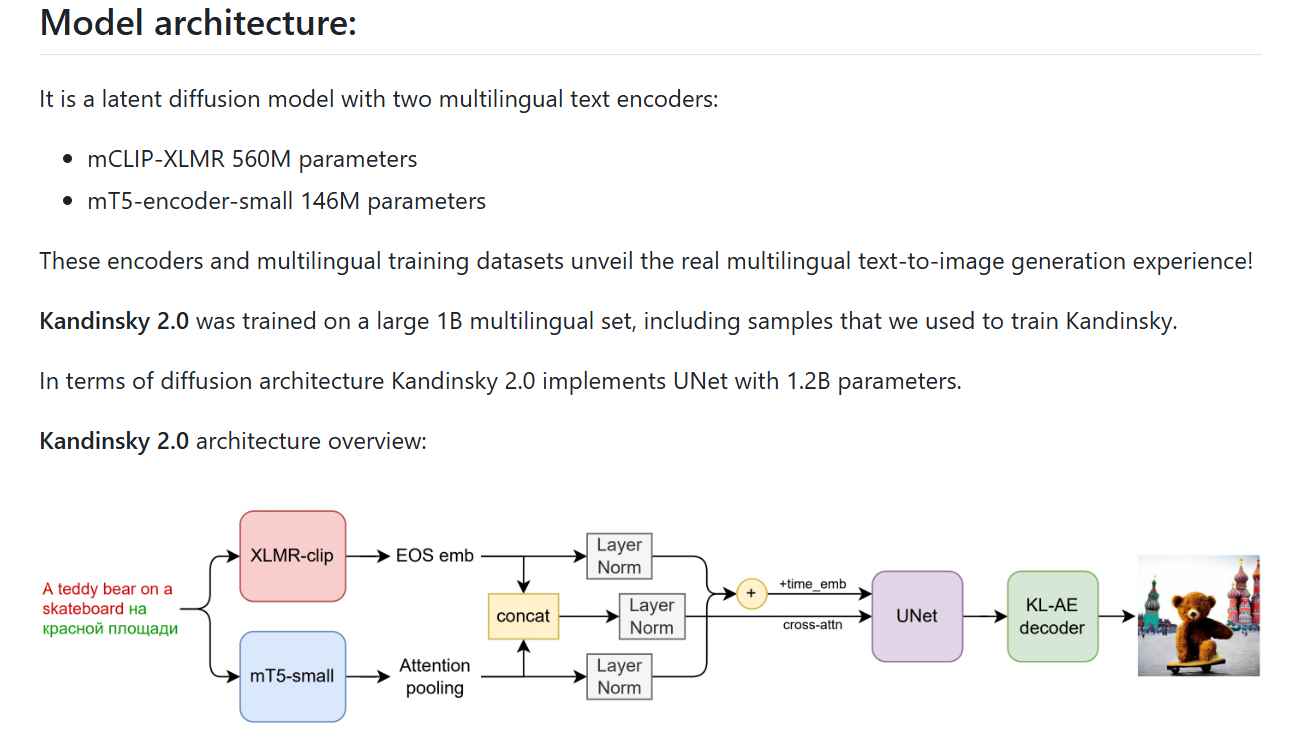
Kandinsky 2 is an advanced multilingual text-to-image generation model based on latent diffusion architecture. It integrates two multilingual text encoders—mCLIP-XLMR (560M parameters) and mT5-encoder-small (146M parameters)—trained on a large-scale dataset of 1 billion multilingual text-image pairs. This design enables high-quality image synthesis from text prompts in multiple languages.
Key Features
Multilingual text-to-image generation supporting various languages.
Incorporates mCLIP-XLMR and mT5-encoder-small for robust text understanding.
Latent diffusion model with a UNet architecture comprising 1.2B parameters.
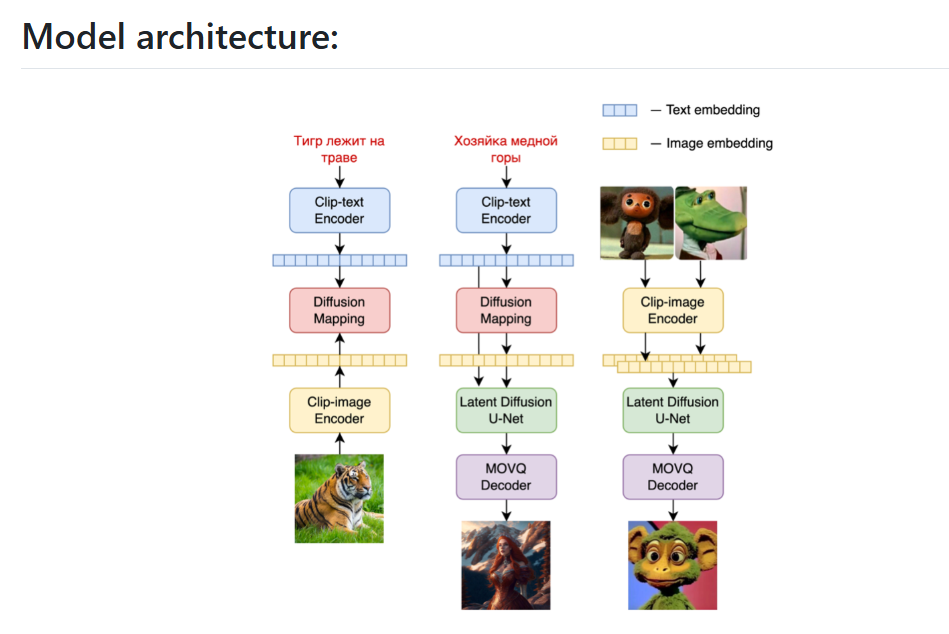
Supports image mixing, inpainting, and image-to-image translation.
Enhanced image quality and text alignment in version 2.2 with the integration of CLIP-ViT-G as the image encoder and ControlNet support.





.png)
.png)