ELECTRA is a sample-efficient pretraining method for transformer-based language models. Instead of masking and predicting tokens like BERT, ELECTRA introduces a discriminative approach where a small generator replaces masked tokens, and a larger discriminator learns to detect which tokens are original and which have been replaced. This method results in faster training and improved performance on a variety of NLP tasks.
Key Features
More compute-efficient than traditional masked language models
Trains using a replacement detection objective instead of masked token prediction
Combines a small generator and a large discriminator
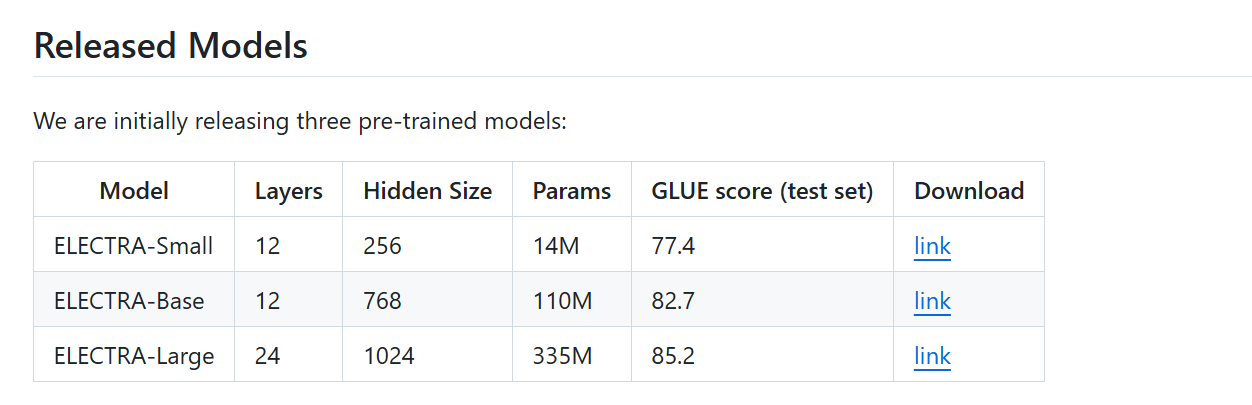
Outperforms BERT on multiple downstream NLP tasks
Open-source implementation with pretrained models and training scripts
.png)
.png)
.png)
.png)
.png)