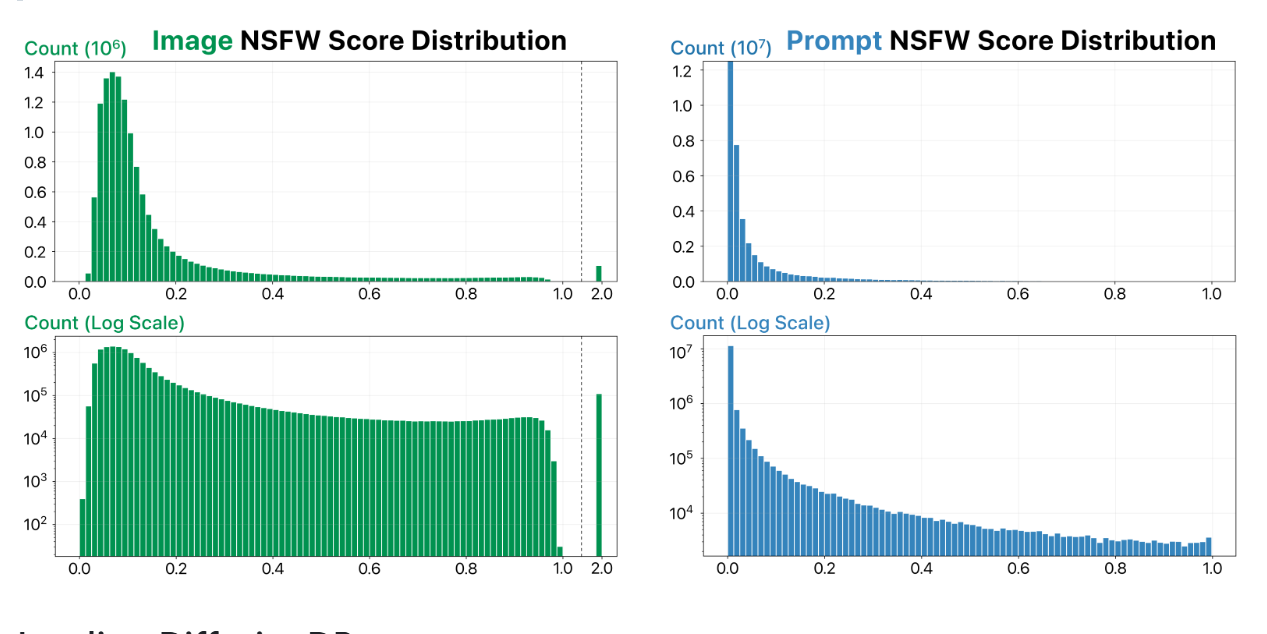
DiffusionDB is the first large-scale dataset of text-to-image prompts, comprising 14 million images generated by Stable Diffusion using prompts and hyperparameters specified by real users. It serves as a valuable resource for understanding the relationship between textual prompts and generated images, facilitating research in prompt engineering, model interpretability, and human-AI interaction.
Key Features
Extensive Dataset: Contains 14 million images and 1.8 million unique prompts.
Rich Metadata: Includes hyperparameters such as seed, CFG scale, steps, sampler, width, and height.
Two Subsets: Offers DiffusionDB 2M (2 million images) and DiffusionDB Large (14 million images) to cater to different research needs.
Flexible Access: Provides multiple methods to access the dataset, including Hugging Face Datasets, a custom downloader script, and metadata files.
Anonymized Data: Ensures privacy by anonymizing user information and removing personal identifiers.


.png)

.png)
.png)